RefDB Features: SRU interface
SRU (Search and Retrieve via URL) is a standard search protocol developed by the Library of Congress to allow web-based access to libraries. RefDB uses a proxy server to provide access to the reference databases via SRU.
| On this page |
| General features |
| Screenshots |
General Features
- RefDB ships two SRU proxy servers. The standalone server is simple to set up and mainly intended for personal use. The CGI version requires a running web server, but it provides the scalability and security for multiuser and remote access.
- The SRU service can be accessed via a web browser (by typing a suitable URL into the location bar or via web forms that generate these URLs), via command-line programs like wget, via dedicated clients like YAZ, or from any program that retrieves bibliographic data via SRU. Among the latter are citeproc, a bibliography formatting tool, and maybe future versions of OpenOffice.
- RefDB supports all three SRU operations: explain, searchRetrieve, and scan, and conforms to CQL Level 2
- The CQL queries can use the context sets Dublin Core (dc) and the not yet officially released CQL Bibliographic Searching (bib).
- The results of all operations are sent back as XML documents. RefDB ships suitable stylesheets to display these result documents in a human-readable fashion in your web browser.
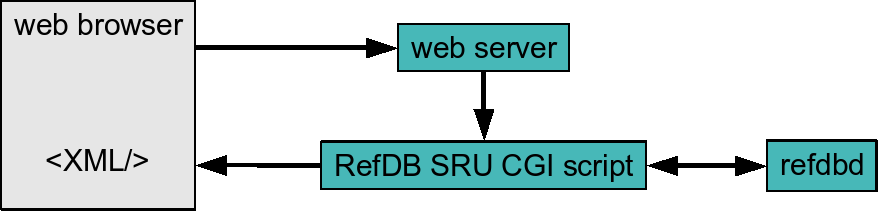
Screenshots
The explain operation

Fig. 1: The result of an explain operation.
The searchRetrieve operation (MODS)
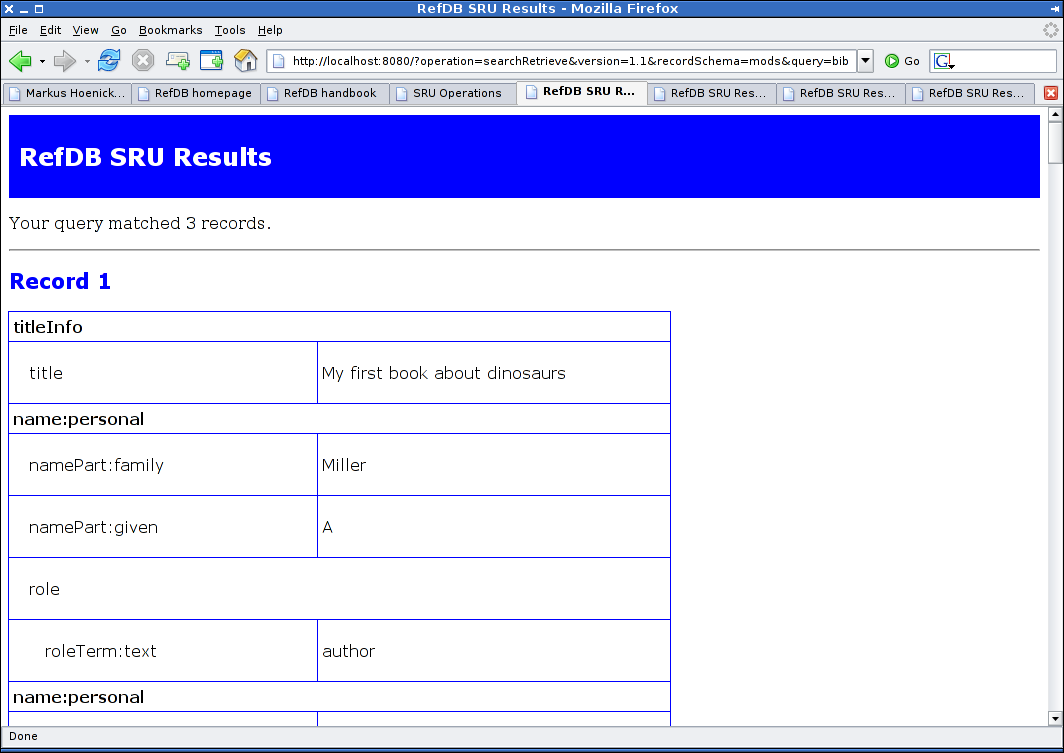
Fig. 2: The MODS result set of a searchRetrieve operation.
The searchRetrieve operation (risx)

Fig. 3: The risx result set of a searchRetrieve operation.
The scan operation

Fig. 4: The result of a scan operation.
Error messages

Fig. 5: The diagnostic message caused by an incorrect query string.