RefDB Features
This page tries to explain what RefDB is and what it's not.
| On this page |
| General features |
| Application design |
| Reference Management |
| Bibliographies |
| Networking capabilities |
| Supported database engines |
| What it's not |
General Features
- RefDB is a reference/notes database and bibliography tool for SGML, XML, and LaTeX documents.
- RefDB is mainly implemented in C, with a few Perl scripts inbetween, as well as shell scripts as "glue". It can be compiled on all platforms with a decent C compiler (a small amount of porting may be required). It builds and runs out of the box on Linux, FreeBSD, NetBSD, Solaris, OS X, Darwin, and Windows/Cygwin.
- RefDB is modular and accessible. You can plug in a variety of database engines to store your data, and you can choose between a variety of interfaces for interactive work. In addition you can use RefDB in your own projects through shell scripts or from Perl programs.
- The RefDB handbook (more than 300 printed pages) helps you to get RefDB up and running quickly and explains how to use the software for both administrators and users in great detail. In addition there is a tutorial targeted at plain users.
Application design
- RefDB uses a SQL database engine to store the references, notes, and the bibliography styles. Choose either an external database server for optimum performance and flexibility, or an embedded database engine for convenience (see below for supported database engines).
- Both reference and bibliography style databases use the relational features of SQL databases extensively to consolidate information and to save storage space.
- RefDB employs a three-tier architecture with lots of flexibility: clients, an application server that can run as a daemon, and the database server. If you prefer the embedded SQL engine, there'll be a two-tier setup. In both cases, all tiers may run on a single workstation for individual use.
- RefDB contains two standard interfaces: a command line interface for terminal addicts and for use in scripts, and a PHP-based web interface for a more visual approach. There is also a standards-compliant SRU interface for read-only access. In addition, both Emacs and Vim users can access RefDB from the editing environment they're used to. Finally, there is also a Perl client module and an experimental Ruby library to integrate RefDB functionality into your own programs.
Reference and notes management
- The main input format for bibliographic data is RIS which can be generated and imported by all major reference databases on Windows (Reference Manager, EndNote and the like). An XML representation of RIS using the risx DTD is also supported as a native format. The latter is well suited as a means to import SGML or XML bibliographic data.
- A
checkrefcommand provides a way to check your incoming data for duplicates, spelling variants, or author and periodical name synonyms before adding your data permanently to the database (example). - Import filters are provided for Pubmed/Medline (tagged and XML), BibTeX, MARC, and DocBook. Additional formats, including MODS, can be converted to RIS by external tools like bibutils.
- The data can be retrieved as simple text, formatted as (X)HTML, formatted as a DocBook
bibliographyelement (SGML or XML), formatted as a TEIlistBiblelement (XML), formatted as a MODS document, formatted as BibTeX reference list, or formatted as RIS or risx files. - All XML data can optionally be retrieved with namespace prefixes and a namespace declaration to use them in compound XML documents.
- The (X)HTML output can optionally size and colour author names, periodical names, and keywords according to their frequencies in the database, thus creating the equivalent of tag clouds of social tagging services (example).
- By default, RefDB uses UTF-8 as the default character encoding for incoming and outgoing data, as well as for the databases. However, all character encodings supported by your platform can be used both for data input and for data export, as RefDB will recode the data transparently. This includes European character sets like Latin-1 and of course Unicode.
- Extended notes can be linked to one or more references, authors, periodicals, or keywords to create topics or material collections. These are more powerful and flexible than folder systems and the like.
- Personal reference lists are a special application of extended notes. Each user has a default list which contains all datasets she added to the database. In addition, each user can create an unlimited number of these lists to organize references by projects, topics, or contexts.
- The query language used in the command-line clients, in the web interface, and in the Perl client library is fairly simple yet powerful. You can use booleans to combine queries on any combination of fields. You can use brackets to group queries. You can use Unix-style regular expressions to formulate advanced queries. In addition, the CQL query language is supported in the SRU interface.
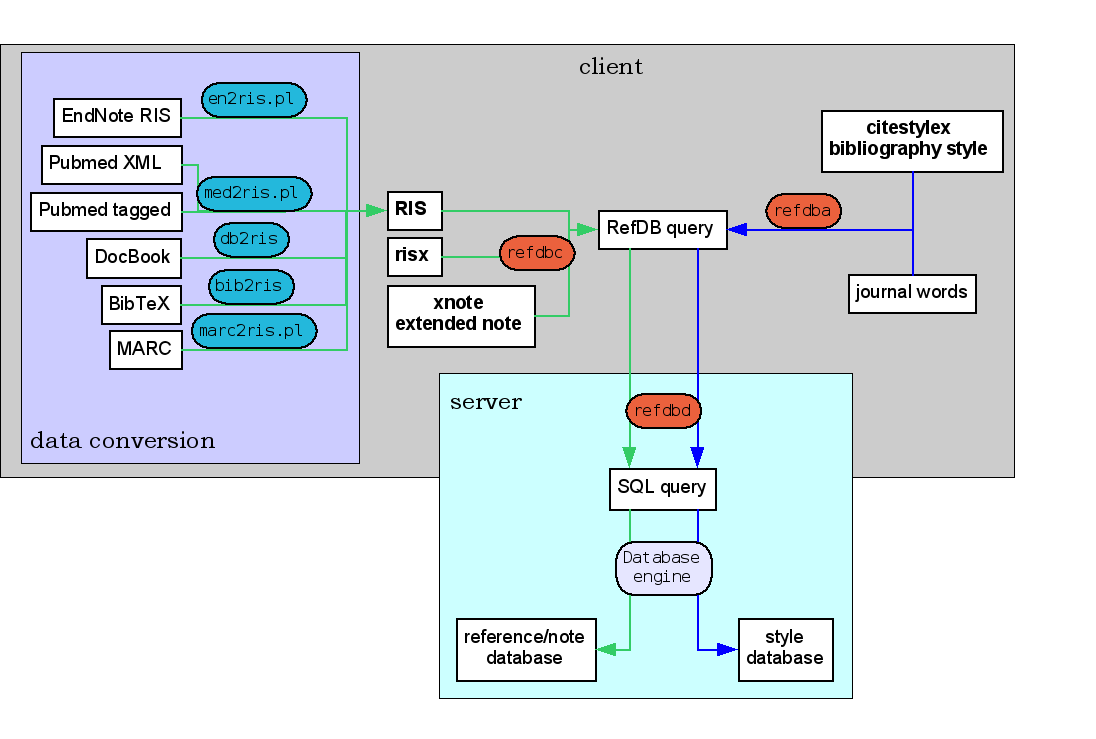
Fig. 1: RefDB data input. Click on the image to see a larger version.
Bibliographies
- Formatted bibliographies can be created automatically from DocBook SGML/XML and TEI XML documents. This does not require any changes or extensions to the DTDs. RefDB can also be integrated as a data source into the LaTeX/BibTeX workflow. Finally, external applications can retrieve raw bibliographies in either risx or MODS formats via the SRU interface.
- Both the DTD-based versions (V.4.x, P4) and the schema-based versions (V.5.x, P5) of DocBook and TEI are supported.
- RefDB is extensible in terms of the supported document types: support for new document types can be added without hacking the tool itself (you only need to hack stylesheets)
- Citation and reference styles can be defined in XML to match the weirdest requirements of journals and publishers.
- RefDB supports numerical, author/year, and citation key citation styles
- Sophisticated shell scripts and makefiles take care of the document transformations. The whole process is transparent to the user as all he needs to do is e.g. type
make pdfto turn his document into a PDF file with formatted citations and bibliographies.
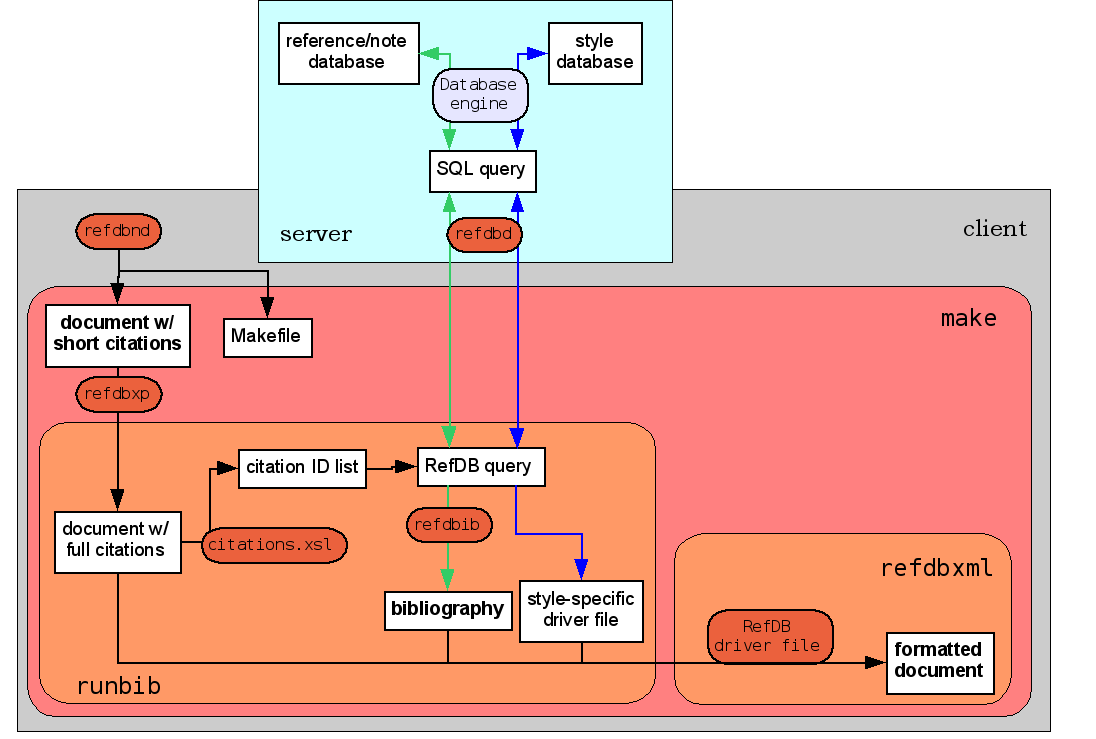
Fig. 2: RefDB bibliography output. The example shows the processing of an XML document to printable output. runbib and refdbxml are shell scripts that can be invoked separately. However, it is more convenient to use the refdbnd-created Makefile which processes your document with a single command. Click on the image to see a larger version.
Networking capabilities
- Due to the client/server design, RefDB is very well suited as a shared reference database for a workgroup or a department. However, it runs just fine on a single standalone workstation.
- Users can share databases and still have their personal reference lists. They can share their notes or keep them private on a per-note base.
- Concurrent read and write access of several users is supported. There is no need to restrict access of other users to read-only. However, if your database engine supports access control (MySQL and PostgreSQL), you can restrict access of some users to read-only.
- A simple method to access electronic offprints (e.g. in PDF or PostScript format) is provided in the HTML output and in the web interface. This also works across networks using mounted shares.
Supported database servers
RefDB versions 0.9 and later employ the libdbi database abstraction library to provide support for different SQL database engines.
Currently the following external SQL database servers are supported:
The following embedded database engines are supported:
- SQLite (versions 2.x and 3.x)
RefDB versions prior to 0.9 use MySQL as the SQL engine.
What it's not
- This is not a graphical pointy-clicky tool (except for the web interface). Be prepared for command lines.
- It is not an integrated package. Instead, it is integrated into your environment, making use of external tools whenever this is possible.