General features
-
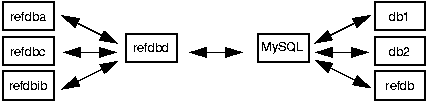
refdb uses a three-tier architecture (see Figure 1-1), consisting of clients on the workstation side, and an application server as well as the SQL database server on the server side.
Optionally you may use an internal database engine instead of the external SQL server, resulting in a simpler two-tier setup.
-
The data storage proper is done by a SQL database engine. Currently MySQL and PostgreSQL are supported as external database engines. Additionally, an internal SQL engine based on SQLite is available, which allows data storage in a single, operating-system and architecture-independent file without any administration overhead.
-
The server can run as a daemon in a non-privileged account if security concerns require this. Besides, users can start it as a standalone application on demand.
-
The refdb clients are no fat applications, but rather a collection of small, portable tools implemented in ANSI C to perform all necessary client-side tasks on any platform with a decent C compiler.
-
The refdb clients can be run in an interactive mode or in a batch mode which is useful in scripts.
-
In addition to the command line clients there is a web interface for the most important reference management functions of refdb
-
The adepts of the Perl programming language might be delighted to know that the RefDBClient module allows Perl programs to directly communicate with a refdbd server without using the C clients. This allows the rapid development of custom programs that access RefDB databases.