Things to know before you start
Where do the components go?
As refdb is a three-tiered client-server application, you have considerable freedom to distribute the components among your computers. Although refdb shines in a network environment, there is absolutely no problem to run all components on a single standalone workstation.
The basic idea of the client-server model has several implications:
-
Many workstations can access a single server running the database server. Thus many people can access the same databases without the pain of duplicating the data and the database engine on every single machine.
-
A considerable part of the computing effort is done outside of the workstations. Therefore even rather lame workstations may be sufficient to access and manipulate the data. The database server should run on a decent machine, though (better not that dusty 486 that has doubled as a paperweight since 1990).
-
Updates of the software will mainly affect the database server and the application server. This considerably reduces your workload, as the workstations need to be updated less frequently.
The most common scenarios for using refdb will be on a department or institute network and on a standalone workstation. Some additional thrill is added by the fact that refdb can also provide a part of its functionality through a CGI-based web interface, so we'll look at this as a third scenario.
Installation on a standalone workstation
This is obviously the simplest case. The clients, the application server, the database server, and the databases reside on the same physical machine (see Figure 4-1). The only requirement for the workstation is that a TCP/IP network is installed. This is necessary as the three layers of refdb always communicate via TCP/IP sockets. The IP address 127.0.0.1 has to be specified in the configuration files of the clients and of the application server.

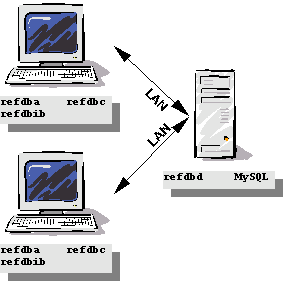
Installation in a network
In a network you can take advantage of the client-server model and distribute the workload between your computers. Although the three layers can well be distributed between three physical machines, it may be more useful to install the application server on the same machine as the database server and the databases (see Figure 4-2). A dedicated or general-purpose server may be most suitable to hold these components, as a workstation may get sluggish if it has to answer a lot of database requests.
The clients as well as scripts and support files have to be installed on all workstations that will be used to access the databases. The client for administrative tasks, refdba, can be restricted to the workstations of system administrators or otherwise experienced staff.
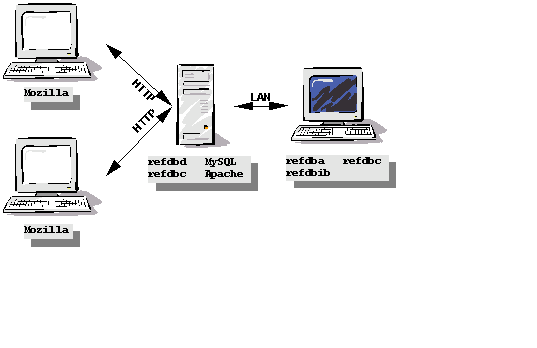
Installation as a web application
You can of course set up the CGI functionality in parallel to any of the above mentioned installations. All you need to do is to keep copies of refdbc, bib2ris, and nmed2ris on the computer that runs your web server (see Figure 4-3). refdbc can be configured to communicate with refdbd on the same or a different computer in the network, so for the rest of the installation you are free to use one of the above scenarios. The command-line clients refdba, refdbc, and refdbib should be available on at least one computer in the network for all those tasks that cannot be performed through the web interface.
The mystery of the configuration files
refdb tries to be a well-behaved Unix-style software package and is thus able to pull a lot of information out of cryptic configuration files. This section tries to introduce you into the mysteries of the various levels of configuration files.
The purpose of the configuration files is to set some reasonable default values for the command-line switches of the refdb programs. Once you have set these, you will never have to specify these values on the command line again, unless you want to temporarily override them.
Types of configuration files
The clients refdbc, refdbib, refdba, as well as the conversion filters bib2ris, db2ris, and nmed2ris can use two configuration files each. One global configuration file is supplied by the system administrator and can be used to set values that are common for all users on that box, like the IP address of the application server. Another file can be used by every user to supply the values that were not set in the global file or to override settings in this file. The users' copies can have a leading dot to hide the files (the refdb programs will first try to read a hidden configuration file, and only if that cannot be found they try to read a non-hidden file).
The application server refdbd uses only one global configuration file.
refdbc, bib2ris, and nmed2ris use a second global configuration file if they are run as a CGI applications. A local configuration file does not make sense in this case.
The default location for the global configuration files is /usr/local/etc (this can be changed by setting --prefix or --sysconfdir appropriately when running ./configure). The user copies of the client configuration files are expected to be in the users' home directories as specified by the environment variable HOME.
Note: For reasons of compatibility with refdb versions prior to 0.8.4, the refdb applications look for configuration files in $REFDBLIB if there is no appropriate file in /usr/local/etc (or whatever you chose). You can "misuse" this feature by providing configuration files that are shared between different computers running refdb programs.
Configuration file syntax
All configuration files share a common syntax. There are just three essential things to know:
-
All information is stored as pairs of whitespace-separated items, one pair on each line. The first item on the line specifies the variable name, the second item specifies the variable value. Whitespace means one or more spaces or tabs in any combination.
-
Everything to the right of a hash sign (#) is a comment. The rest of the line is ignored.
-
The line endings are Unix-style (0x10, not DOS-style 0x13 0x10)
A configuration example
The whole configuration stuff may sound a bit confusing, so let us now look at a simple configuration example that illustrates the principles laid out above.
The following is a listing of /usr/local/etc/refdbcrc, our global refdbc configuration file in this example:
# This is the global configuration file for refdbc
serverip 127.0.0.1
port 9734
pager more
timeout 60
# end of refdbcrc
|
This is the corresponding copy that one of the users of the system created as /home/markus/.refdbcrc:
# This is the user configuration file for refdbc
pager less
username markus
passwd *
timeout 30
# end of .refdbcrc
|
As you can see our hypothetical system administrator configured the IP address (serverip) and the port where refdbd listens to the client requests. This value is most likely the same for all users on the system, so this is nothing to worry about for the users. more is defined as the default pager, and the timeout is set to 1 minute.
The hypothetical user does not like more as a pager and prefers to use less instead. He also thinks that half a minute as a timeout should be enough. Both of these settings override the corresponding values in the global file. serverip and port are not redefined in the user's copy, so the values of the global file take effect. The prudent user also defined username and passwd so the correct values will be used for the database access (the asterisk in the passwd field will cause refdbc to ask for the password interactively for security reasons).
Environment variables
refdb uses a few environment variables to locate the files and directories it needs to run properly. The following list describes all environment variables that affect the operation of refdbd and its clients.
- HOME
-
This variable should be set for all users anyway. It is used to locate the personal configuration files for the refdb clients.
- REFDBLIB
-
Note: Support for the REFDBLIB environment variable is only for backwards compatibility. Since version 0.8.5, the recommended way to provide the information contained in REFDBLIB are "refdblib" entries in the configuration files. The advantage of the latter is that these entries can be automatically generated during the installation and that they work in CGI programs as well.
This variable is used to locate the directories in which bibliography specification files, stylesheets, web page templates, and DTDs are stored. The value of this variable is actually determined during the configuration process, as it is the same as the package data directory. The default is /usr/local/share/refdb, but you can change this when configuring the sources (see below).