Chapter 1. General design and feature highlights
- Table of Contents
- Feature list
- Design of the bibliography tools
- Credits
Feature list
-
The whole project reuses as much existing software as possible. This means e.g. that the package does not have it's own database engine and does not have a built-in editor.
-
In good Unix style, reference data are imported from text files or from stdin and exported to text files or to stdout. This means that to create or edit references any general purpose text editor like Emacs (yes, and vi; even notepad <shiver>) will do. This also means that you have the full power of all those Unix tools at your disposal to create or modify references. The file format sticks closely to the RIS specification that most Windows-based reference managers understand. The major difference is the LF vs. CR/LF issue.
-
Input filters can be used to convert references from various sources to the RIS format. Currently refdb ships with Medline, BibTeX, and DocBook filters. You are free to use or write any other input filter that you may need. These filters must either create an output file or write the results to stdout for further plumbing. This way, input filters can be written in almost any programming language and it should be easy to extend the list of reference information formats that refdb can import.
-
The data storage proper takes place in an existing SQL database application (currently MySQL, but support for both mSQL and PostgreSQL is work in progress).
-
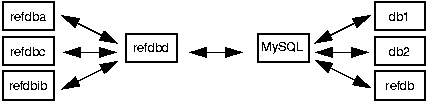
refdb uses a three-tier architecture (see Figure 1-1), consisting of clients on the workstation side, and an application server as well as the SQL database software proper on the server side. This design decision was made as MySQL is still in heavy development. The application server can be adapted to new features in MySQL without changing the clients on every single workstation.
-
The application server refdbd is implemented as a forking server, i.e. it runs a child process for every client request. While this is somewhat more expensive in terms of memory than a multithreaded server, this simpler solution is acceptable due to the small memory footprint of refdbd (approx 225 kb on a Linux system).
-
The refdb clients are no fat applications, but rather a collection of small, portable tools implemented in ANSI C to perform all necessary client-side tasks on any platform with a decent C compiler.
-
The refdb clients can be run in an interactive mode or a command line mode which is useful in shell scripts.
-
The client tasks include:
-
Add, modify, and remove reference entries
-
Search for reference entries
-
Perform global search&replace operations
-
Perform import and export from and to other databases via the common interchange format RIS
-
Generate bibliographies
-
-
The query language is fairly simple yet powerful. You can search in all fields in the database. You can use the Boolean operators AND, OR, NOT to combine search expressions. You can use brackets () to group search expressions. All alphanumeric fields (i.e. most except e.g. the publication year) treat the search string as a Unix-style regular expression which gives you enormous flexibility in your search strategies. The readline library reads the user input in all interactive clients. You can recall any previous search strings with a few keystrokes and re-run them or modify them as needed.
-
The query results can be displayed in a variety of formats. The standard backends create screen, HTML, BiBTeX, and DocBook formats. All output can either be viewed on stdout or with a pager, or the output can be redirected into a file or into a pipe for further manipulation. refdb provides a simple API to implement custom backends if you need other output formats.
-
refdb can create formatted bibliographies for DocBook and TEI documents. The formatting can be customized to match the requirements of any publisher or journal.
-
In addition to the command line clients there is a web interface for the most important reference management functions of refdb
-
refdb handles the AV field of the RIS input files in a very flexible way. You can specify a path to a PDF or Postscript version of the document on your harddrive or on the web. The local path can be split into a variable and a static part. The variable part can be specified on the command line e.g. if you access your data remotely via a NFS-mounted share.
-
refdb knows the concept of a personal reference list. This feature is useful if a database is shared among several users in a workgroup. In this case, all users benefit from the larger stock of references available in the database. There are two common complaints about this approach:
-
"I'm not interested in the junk others read. They just clog the database."
-
"I want to have my own database so I can leave this group anytime and take my data with me."
To rectify this, refdb keeps track of the user who added a reference to the database. A switch to the addref command allows to override the default name, so administrative staff or dear colleagues can enter references on your behalf. You can use a switch in the getref command to restrict your search on those references that are associated with your username. On the other hand, if you find out that even your colleagues have one or two interesting papers, you can use the pickref command to add these references to your personal reference list. The personal part of the reference information (the reprint status, the availability, and the notes) are saved for each user individually.
-