Chapter 7. Data input
- Table of Contents
- Writing RIS datasets
- The Emacs RIS mode
- Input filters
This chapter explains the ways how you can generate reference data suitable for the database. We'll cover manual generation of RIS files and automatic conversion of other bibliographic data with the help of input filters.
To actually import the resulting RIS datasets into the refdb database, use the addref command of the refdbc command line client, as explained in the next chapter.
Writing RIS datasets
Overview
The RIS format is a tagged file format with the following general rules:
-
A file can hold one or more references
-
Each reference starts with a newline. This also means that every RIS file starts with an empty line.
-
There can be only one tag per line.
-
The tag must be at the very beginning of the line.
-
If the contents following a tag are very long, the logical line may be split by appending a slash "/" to the end of each screen line to increase human readability. The next line(s) must not use a tag.
-
The tags consist of two capital letters denoting the type, followed by two spaces, a dash, and another space.
-
The first tag of each reference is the Type tag (TY - )
-
The last tag of each reference is the End tag (ER - )
-
The sequence of all other elements is arbitrary.
Therefore a minimal RIS file may look like this:
|
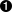
- This is the empty line generated by a linefeed character (0x0A) that precedes every RIS citation, even at the start of a RIS file.
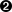
- This is the mandatory first tag, the type specifier. In this case, we're looking at a BOOK entry.
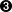
- This and the following lines are the contents proper of the citation. All additional tags would go here as well
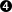
- This is the mandatory last tag which closes the citation. Although invisible here, this tag also has a trailing space like all others.
RIS tags
The following list shows all available tags and their use.
Note: Please keep in mind that a full tag consists of the letters mentioned below followed by two spaces, a dash, and another space. E.g. the first tag below would be written as "TY - " in a RIS file.
- TY
-
This tag specifies the type of the reference and must be the first tag of each RIS dataset, preceeded by a newline.
Format: This can be any of the following strings:
-
ABST (abstract reference)
-
ADVS (audiovisual material)
-
ART (art work)
-
BILL (bill/resolution)
-
BOOK (whole book reference)
-
CASE (case)
-
CHAP (book chapter reference)
-
COMP (computer program)
-
CONF (conference proceeding)
-
CTLG (catalog)
-
DATA (data file)
-
ELEC (electronic citation)
-
GEN (generic)
-
ICOMM (internet communication)
-
INPR (in press reference)
-
JFULL (journal - full)
-
JOUR (journal reference)
-
MAP (map)
-
MGZN (magazine article)
-
MPCT (motion picture)
-
MUSIC (music score)
-
NEWS (newspaper)
-
PAMP (pamphlet)
-
PAT (patent)
-
PCOMM (personal communication)
-
RPRT (report)
-
SER (serial - book, monograph)
-
SLIDE (slide)
-
SOUND (sound recording)
-
STAT (statute)
-
THES (thesis/dissertation)
-
UNBILL (unenacted bill/resolution)
-
UNPB (unpublished work reference)
-
VIDEO (video recording)
-
- ER
-
This empty tag denotes the end of the reference. It must be the last tag of each RIS dataset.
- ID
-
This is the unique ID that refdb generates when a reference is imported into a database.
Note: You should not create the ID tag manually. It is ignored when adding the dataset, but it may overwrite an existing entry if you update a reference. Along the same line, you should leave the ID tag alone if you retrieve a dataset from the database and plan to update it.
Format: Integer >0.
- TI
-
This is the title of a publication. For BOOK and UNPB references this is the same as the BT tag.
Format: A string with unlimited length.
- T2
-
This is the secondary title of a publication, e.g. the book title for a CHAP reference.
Format: A string with unlimited length.
- T3
-
This is the tertiary title of a publication, e.g. the series title for a CHAP reference.
Format: A string with unlimited length.
- AU
-
Synonym: A1. This is the name of one author of the reference. If a reference has multiple authors, each author is specified with an AU tag on a separate line. The number of authors per RIS dataset is not limited. The sequence of the authors in the authorlist will be determined from the sequence as they appear in the RIS dataset.
Format: A string with up to 255 characters in the form: Lastname,X.[Y. ...][,Suff.]. The firstnames and middle initial must be abbreviated. It is not possible to use more than one middle initial.
- A2
-
Synonym: ED. This is the name of an editor of the reference, e.g. an editor of the book in which a CHAP reference was published. The same restrictions as for AU apply.
- A3
-
This is the name of a series editor of the reference, e.g. an editor of a series of books in one of which a CHAP reference was published. The same restrictions as for AU apply.
- PY
-
Synonym: Y1. This is the primary publication date.
Format: A string with the format "YYYY/MM/DD/otherinfo", where YYYY denotes the four-digit year, MM and DD denote the two-digit month and day, respectively, and otherinfo denotes any other information with up to 255 characters. If any of these parts is not available, it can be left out, but the slashes must be present. E.g. "1999///Christmas edition" is a valid string.
- Y2
-
This is the secondary publication date.
Format: A string with the format "YYYY/MM/DD/otherinfo", where YYYY denotes the four-digit year, MM and DD denote the two-digit month and day, respectively, and otherinfo denotes any other information with up to 255 characters. If any of these parts is not available, it can be left out, but the slashes must be present. E.g. "1999///Christmas edition" is a valid string.
- N1
-
The notes. This can be any form of additional information, like pointers to corrections or editorials, or just personal notes about the contents of the reference.
Format: A string with unlimited length
- N2
-
Synonym: AB. The abstract of a reference.
Format: A string with unlimited length
- KW
-
A keyword. If a publication has multiple keywords, each goes on a separate line preceeded with this tag. Keywords are crucial to find references in larger databases.
Format: A string with up to 255 characters
- RP
-
The reprint status of a reference. This can be any of the following strings:
-
IN FILE
-
NOT IN FILE
-
ON REQUEST MM/DD/YY
-
- SP
-
The start page of the reference
Format: A string with up to 255 characters
- EP
-
The end page of the reference
Format: A string with up to 255 characters
- JO
-
The abbreviated name of a journal.
Format: A string with up to 255 characters. The journal words should be separated by a single space without a period after abbreviated words. If you use periods, these should not be followed by spaces.
- JF
-
The full name of a journal.
Format: A string with up to 255 characters
- J1
-
The abbreviated name of a journal (user abbreviation 1).
Format: A string with up to 255 characters
- J2
-
The abbreviated name of a journal (user abbreviation 2).
Format: A string with up to 255 characters
- VL
-
The volume of the journal.
Format: A string with up to 255 characters
- IS
-
The issue of the journal
Format: A string with up to 255 characters
- CY
-
City of publication of a book.
Format: A string with up to 255 characters
- PB
-
Name of the publisher or the publishing company.
Format: A string with up to 255 characters
- SN
-
The ISBN or ISSN number.
Format: A string with up to 255 characters
- AD
-
The contact address, usually the any combination of postal or email address and the phone or fax number of the corresponding author.
Format: A string of unlimited length
- UR
-
The URL of an online version of the reference.
Format: A string with up to 255 characters
- U1 through U5
-
The user-defined fields 1 through 5. These fields are not intended to be filled with random bits of information. Each database should have a set of rules what information is to be stored in these fields.
A possible use for these fields is some relevance indicator (e.g. "*" means low, "*****" means high relevance).
You may also use one of these fields to create the equivalents of "folders" that some other reference databases praise as the panacea to organize your references. Just assign the same value to one of these fields for all references that belong to the same folder. Retrieve them by specifying this value in addition to your other search criteria.
Format: A string with up to 255 characters
- M1 through M3
-
The miscellaneous fields 1 through 3. The distinction between Ux and Mx fields is somewhat unclear, and maybe only the inventors of the RIS format have a vague idea why there are two different types of fields for user-defined information.
Format: A string with up to 255 characters
Examples
The following listing shows a few examples of valid RIS datasets.
Note: Long entries like abstracts were divided into several lines using slashes. This is not mandatory, but makes it more human-readable for this manual.
TY - JOUR T1 - T-lymphocytes from normal human peritoneum are phenotypically / different from their counterparts in peripheral blood and CD3- lymphocyte / subsets contain mRNA for the recombination activating gene RAG-1 A1 - Hartmann,J. A1 - Maassen,V. A1 - Rieber,P. A1 - Fricke,H. Y1 - 1995/// KW - Peritoneum KW - T cell KW - T lymphocyte KW - lymphocyte KW - immunology KW - CD3 KW - human KW - Adult KW - blood RP - IN FILE SP - 2626 EP - 2631 JF - European Journal of Immunology JA - Eur.J.Immunol. VL - 25 N2 - These findings are compatible with the hypothesis that the adult / human peritoneum provides a microenvirinment capable of supporting a / thymus-independent differentiation of T lymphocytes. ER - TY - BOOK T1 - Porphyrins and metalloporphyrins A1 - Smith,K.M. Y1 - 1975/// KW - Porphyrins KW - Metalloporphyrins KW - Spectrophotometry [methods] KW - spectroscopy RP - NOT IN FILE CY - Amsterdam PB - Elsevier Scientific Publishing Company ER - TY - CHAP T1 - Physiological studies of the natriuretic peptide family A1 - Lewicki,J.A. A1 - Protter,A.A. Y1 - 1995/// N1 - Atrial Natriuretic Peptide Cardiac synthesis and secretion of / ANP Regulation of ANP Gene Expression Regulation of ANP Release / ANP Receptors Biologic Actions of ANP Brain Natriuretic Peptide (BNP) / BNP Structure Biosynthesis of BNP Biological Actions of BNP C-Type / Natriuretic Peptide (CNP) Biologic Actions of CNP Modulators of / Natriuretic Peptide Clearance Effects of Clearance Receptor Blockers / Effects of Neutral Endopeptidase Inhibitors Role of the Natriuretic / Peitedes in Physiology and Disease Hypertension Congestive Heart / Failure Supraventricular Tachyarrhythmias Acute Renal Dysfunction KW - natriuretic KW - ANF KW - ANP KW - receptors KW - BNP KW - CNP KW - hypertension KW - congestive heart failure KW - review KW - cardiac KW - regulation KW - gene expression KW - expression KW - brain KW - structure KW - biosynthesis KW - receptor KW - inhibitor KW - physiology KW - renal KW - study KW - Peptides KW - atrial natriuretic peptide KW - MODULATOR KW - secretion KW - Gene Expression Regulation RP - IN FILE SP - 1029 EP - 1053 VL - 2 T2 - Hypertension: Pathophysiology, Diagnosis, and Management A2 - Laragh,J.H. A2 - Brenner,B.M. IS - 61 CY - New York PB - Raven Press, Ltd. ER - |