Storing bibliographic data in computer systems is a surprisingly daunting task. There is a variety of data formats for a variety of purposes: bibtex (popular among computer scientists and math wizards), RIS (popular in the biomedical field), MODS (a library format endorsed by the the LOC), to name a few. Rbib is a format that tries to overcome the limitations of bibtex, to avoid the ugliness of RIS, and to avoid the complexity overkill offered by MODS.
The RelaxNG schema is available as an archive
Rbib was designed to serve two purposes:
This first attempt at an implementation admittedly builds on the risx.dtd, a XML DTD that tried to capture the RIS format in an XML data format. The schema consists of three files, separating three logically different parts:
Rbib is best used in conjunction with an XML editor that supports validation during data entry. Several commercial editors are available, but Emacs with nxml-mode (freely available for most platforms) is hard to beat.
rbib distinguishes three levels of bibliographic information. The centerpiece is the monographic information, which roughly corresponds to an item in a library that you can take off the shelf as such (think of a book). A monograph may contain parts which are entities by themselves, but you can't find them individually in a library (think of a chapter in a book collecting the contributions of several authors to a topic). This is encoded in the analytical information. On a larger scale, a monograph may be part of a limited series (think of a complete edition of all books written by a particular author). This goes into the series information. Individual data types may use one or more of these levels to encode the required information. The schema was designed to allow each container type (monographic or serial) to be used also as a standalone data type.
The element library defines all elements that particular reference types might want to store in a database. This is reasonably easy for a database programmer to translate into a database schema which can hold all the required information. But how does RelaxNG help the reference data author to fill in the required data? Let's look at some examples. Most reference types require the publication element (the element that holds monographic data). The following definition in rbib-library.rnc defines the superset of all elements that might ever end up in the publication element:
publication =
element publication { pubtitle, title, author+, edition, volume, refdate, publisher, publication-typespecific, serial }
Some "elements" like publication-typespecific and refdate are named patterns which in turn consist of several XML elements, but don't let yourself get distracted by this. Now let's have a look at two reference types that use the publication element in different ways:
book-publication = element publication { pubtitle, title, author+, shortrefdate, edition?, volume?, publisher?, serial? }
datafile-publication = element publication { pubtitle }
You certainly didn't miss that the publication element of the datafile reference type is allowed to hold only one element - the title. If you try to add anything else, the dataset will be invalid and you'll immediately see that you've added all required info. On the other hand, the publication element of the book reference type allows additional elements, but not all that are available in the library - it is just a different selection from what's available. This way, a validating XML editor can guide you through each entry and help you add whatever is required (and allowed) for a particular reference type.
Another advantage of the use of RelaxNG patterns is that reference types can share parts of their structure, or even the complete structure, thus reducint the bloat of the schema. In the latter case, the different data types are used only to record the nature of the reference. E.g. the journalarticle and journalabstract types share exactly the same structure. But as some journals insist on formatting paper and abstract references differently, we have to record the nature of the reference. We can't infer it from the structure.
As said previously, rbib builds on RIS and currently offers the reference types that RIS supports (with a few exceptions, see below). I've currently refrained from including additional types, although a few of them should be added lateron. The design of the schema allows the assembly of custom types from the available pool of elements.
The following data types use analytical information at the lowest level:
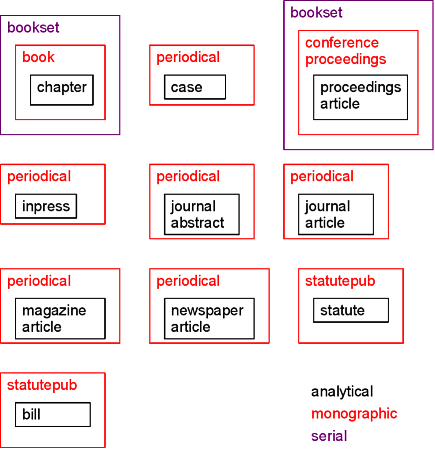
The following data types use monographic information at the lowest level:
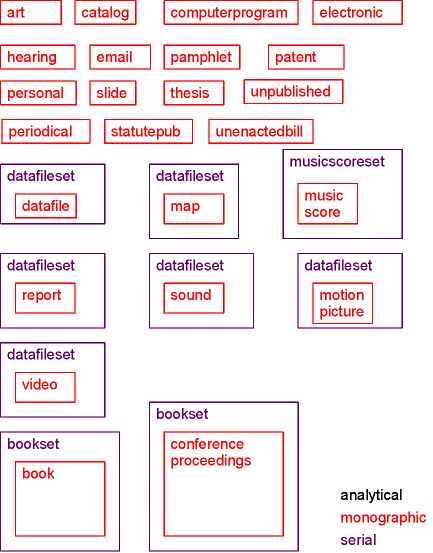
The following data types use series information at the lowest level:
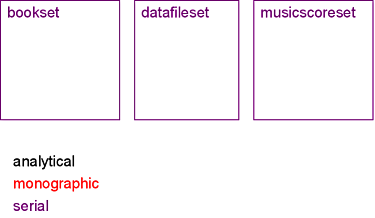
A description of a schema hardly gets away without showing examples. However, you should keep in mind that the unique strength of the Rbib schema is not readily visible in the resulting XML data, but rather in the process of generating the latter - something that is hard to convey with example data. You have to try it out using a validating XML editor.
<chapter citekey="chapter1999" id="55">
<part>
<parttitle>
<full>The synthesis of benzylindazoles</full>
</parttitle>
<author role="author">
<lastname>Miller</lastname>
<firstname>Robin</firstname>
<middlename>M</middlename>
<suffix>Jr.</suffix>
<displayname>Robin M. Miller</displayname>
</author>
<startpage>11</startpage>
<endpage>22</endpage>
<issue>issue</issue>
</part>
<!-- could be encoded by publication+set as well -->
<relation role="containedin">bookcitekey</relation>
<doi>02943871209847</doi>
<abstract>How to synthesize benzylindazoles.</abstract>
<address>University of Texas, Medical School, Fannin Str., Houston TX, USA</address>
<keyword>chemistry</keyword>
<keyword>synthesis</keyword>
<link type="fulltext">http://www.onlinechapters.com/Miller/Miller2004.html</link>
<libinfo user="me">
<notes>Good stuff</notes>
<reprint status="infile">
<date>2006-01-02</date>
</reprint>
<availability type="useroot">epub/Miller2004.pdf</availability>
<date>2006-01-01</date>
</libinfo>
</chapter>
<journalarticle citekey="miller1999" id="4">
<part>
<parttitle>
<full>The secret life of invertebrates on Mount Everest during full moon</full>
<abbrev>Invertebrates on Mount Everest</abbrev>
</parttitle>
<author role="author">
<lastname>Miller</lastname>
<firstname>John</firstname>
<middlename>D</middlename>
<suffix>Jr</suffix>
<displayname>John D. Miller</displayname>
</author>
<refdate>
<date1>
<date>2005-04-01</date>
<dateinfo>April issue</dateinfo>
</date1>
</refdate>
<startpage>55</startpage>
<endpage>59</endpage>
<volume>33</volume>
<issue>2</issue>
</part>
<publication>
<pubtitle>
<full>The Journal of Irreproducible Results</full>
<abbrev>J.Irrep.Res.</abbrev>
</pubtitle>
<publisher>
<publishername>Elsevier</publishername>
<pubplace>Oxford</pubplace>
</publisher>
</publication>
<doi>238012701274</doi>
<abstract>Invertebrates do quite unexpected things during full moon.</abstract>
<address>The Hilton, Monaco</address>
<keyword>unbelievable</keyword>
<link type="image">http://www.jirep.com/images/dancingbug.jpg</link>
<libinfo user="me">
<notes>Unheard of. Amazing!</notes>
<reprint status="infile">
<date>2005-05-01</date>
</reprint>
<availability type="useroot">epub/Miller2005.pdf</availability>
<date>2005-06-01</date>
</libinfo>
</journalarticle>
<email citekey="email2005" id="56">
<publication>
<pubtitle>
<full>How's it going?</full>
</pubtitle>
<title>Personal communication</title>
<author role="author">
<lastname>Hoenicka</lastname>
<firstname>Markus</firstname>
<displayname>Hoenicka, Markus</displayname>
</author>
<author role="recipient">
<lastname>Doe</lastname>
<firstname>John</firstname>
<displayname>Doe, John</displayname>
</author>
<refdate>
<date1>
<date>2005-12-24</date>
<dateinfo>dateinfo</dateinfo>
</date1>
</refdate>
<emailsender>mhoenicka@users.sourceforge.net</emailsender>
<emailrecipient>john.doe@gmail.com</emailrecipient>
</publication>
<abstract>The abstract</abstract>
<keyword>xmas</keyword>
<keyword>greetings</keyword>
<libinfo user="markus">
<notes>Should have sent this years ago</notes>
<reprint status="infile"/>
<availability type="useroot">mails/20051224Doe.pdf</availability>
<date>2005-12-25</date>
</libinfo>
</email>